
Dreamtonics Vocoflex Live Vocal Transforming mit AI-Unterstützung

Test: Dreamtonics Vocoflex Vocal Transforming, Stage, Plug-in
Die Dreamtonics Vocoflex Live Vocal Transforming Software ist ein einzigartiges Tool, das sich an den Live-Performer richtet, der in Echtzeit seine Stimme verändern möchte. Tools zum Verändern der Stimmcharakteristik gibt es bereits zahlreiche, auch als Hardware-Tools für die Bühne. Was Vocoflex Live Vocal Transforming von anderen Produkten unterscheidet, ist die Stimmanalyse beliebiger Stimm-Samples und das Morphing zwischen verschiedenen Stimmen. Taugt die Software bereits jetzt für den Live-Einsatz? Wir haben uns das näher angeschaut.
Inhaltsverzeichnis
Dreamtonics
Dreamtonics ist ein kleines Startup-Unternehmen aus Japan, genauer gesagt aus Tokyo. Das Unternehmen, das seit 2019 besteht, hat sich auf elektronische Musik und Stimmtechnologien wie der Stimmsynthese spezialisiert. Einigen Lesern ist Dreamtonics vielleicht durch die Software-Synthesizer V bekannt, mit der sich beliebige Melodien mit einer computergenerierten Stimme versehen lassen. Während sich Synthesizer V an Studioanwender richtet, ist Vocoflex für die Bühne gedacht, kann aber auch im Studio eingesetzt werden. Die Vocoflex Software befindet sich aktuell noch im Beta-Stadium, steht aber kurz vor der Veröffentlichung. Wir durften die Beta-Version bereits für euch testen.
Dreamtonics Vocoflex Live Vocal Transforming
Vocoflex gibt es als Plug-in und Standalone-Software für Windows PCs und Apple Mac Computer. Es wird im Bundle mit der Stimmsynthese-Software Synthesizer V erhältlich sein und als einzelnes Produkt. Die Plug-in-Version steht als AU für Macs und VST3 für PCs zur Verfügung. Die Systemvoraussetzung für Windows ist ein Computer mit Windows 11 und mindestens i5-7300U oder Ryzen 3 3300U Prozessor. Es werden außerdem mindestens 4 GB RAM benötigt, um sinnvoll mit Vocoflex arbeiten zu können.

Vocoflex bietet einen Low Latency Mode, sodass auch Live-Gesang möglich werden soll
Arbeitsweise
Die Dreamtonics Vocoflex Live Vocal Transforming Software ist sehr einfach aufgebaut. Sie besteht aus einem Programmfenster mit nur sehr wenigen Bedienelementen. Auf der linken Bildschirmseite befindet sich ein Gain-Regler für den Audioeingang der Software. Am oberen Bildschirmrand entdecke ich das Preset-Menü, in dem sich Presets speichern und wieder aufrufen lassen. Außerdem kann man hier das Programmfenster zurücksetzen auf den Ausgangszustand.

Das Programmfenster nach dem Start der Software/des Plug-ins
Eine Checkbox für den Realtime-Modus ermöglicht den Live-Einsatz der Software oder des Plug-ins. Ist die Checkbox gesetzt, lässt sich rechts daneben aus dem Dropdown-Menü aus vier Punkten auswählen, ob eher eine geringe Latenz oder eine hohe Qualität gewünscht ist. Das Settings-Menü in der rechten oberen Ecke ist über das kleine Zahnrad-Icon zugänglich. In der Standalone-Version der Software stellen wir hier unter anderem die verwendete Audio-Hardware für den Toneingang und -Ausgang sowie den Buffer ein. In der Plug-in-Version erledigt das die Host-Software und wir können hier lediglich das Interface zwischen Englisch, Japanisch und Chinesisch umschalten.
Die rechte Bildschirmseite zeigt zwei Werkzeuge. Das obere Werkzeug aktiviert den integrierten Stimmsynthesizer, mit dem sich eine Stimme durch das Verschieben eines Punktes in einer zweidimensionalen Matrix erzeugen lässt. Die Matrix funktioniert ähnlich wie ein Colorpicker. Unten wird ein Hex-RGB-Wert angezeigt, der sich auch manuell über die Tastatur eingeben lässt. Auf der x-Achse bewegen wir uns zwischen einer männlichen und einer weiblichen Stimmfarbe. Die y-Achse beschreibt die Tonalität der Stimme bzw. die Klangfarbe. Über eine Zufallsfunktion lässt sich ein zufälliger Farbraum erzeugen, in dem wir uns bewegen können. Mit Apply bestätigen wir unsere Stimmauswahl, die dann im Anschluss ins Hauptfenster übertragen wird.

Erzeugen einer Stimme mit einer Matrix
Das untere Werkzeug öffnet einen Dateidialog, über den sich eine Stimme als Audiodatei öffnen lässt. Diese wird dann von der KI in der Dreamtonics Vocoflex Live Vocal Transforming Software analysiert und im Anschluss als kleine Kette im Hauptfenster angezeigt.
Am unteren Bildschirmrand befindet sich ein weiterer Regler, mit dem sich das Eingangsmaterial transponieren lässt.
Hat man eine oder mehrere Stimmen ins Hauptfenster importiert, verändert sich der Cursor in eine Art Lichtquelle. Diese Lichtquelle scheint aus einer vom Anwender zu bestimmenden Richtung auf die dargestellten Stimmen. Eine Stimme oder Stimmelemente, auf die Licht fällt, werden hervorgehoben. Eine Stimme oder Stimmelemente im Schatten werden gedämpft. Bewegt man sich im Umfeld mehrerer Stimmen, zeigt die Software durch Linien an, wie viele Anteile der jeweiligen Stimmen zusammengeführt werden. Das, was die Dreamtonics Vocoflex Software hier macht, ist im Prinzip nichts anderes als Morphing zwischen Stimmen.

Morphing zwischen Stimmen anhand einer Lichtquelle: Elemente im Schatten werden abgesenkt, Elemente im Licht verstärkt
Ein einmal gefundenes Setting lässt sich als Preset speichern und später wieder aufrufen. So kann man sich eine Stimmbibliothek anlegen und schnell zwischen den einzelnen Presets wechseln.
Latenz von Dreamtonics Vocoflex
Wie man sich vorstellen kann, erfordert die umfangreiche Bearbeitung einer Stimme Zeit. Die Verarbeitungszeit von Vocoflex muss zur Latenz des Audiointerfaces hinzugerechnet werden, kommt also noch zur Eingangs- und Ausgangslatenz hinzu. Das Vocoflex Live Vocal Transforming Plug-in und die Standalone-Version sind also einerseits vom eingestellten Buffer und der dadurch erzeugten CPU-Last abhängig, andererseits zudem von der eigenen Verarbeitungszeit, die für das Vocal Transforming benötigt wird.

Qual der Wahl: niedrige Latenz oder hohe Audioqualität
Hat man im Programmfenster den Haken für die Aktivierung des Real-time-Modes gesetzt, hängt die resultierende Gesamtlatenz von der Auswahl im daneben befindlichen Dropdown-Menü ab und lässt sich in vier Stufen einstellen. In der Stufe mit der geringsten Latenz ist die Audioqualität leicht herabgesetzt. Die Stufe mit der höchsten Latenz besitzt demzufolge die höchste Audioqualität. Im Highest-Quality-Mode beträgt die Roundtrip-Latenz 160 Millisekunden, im Lowest-Latency-Mode beträgt sie 45 Millisekunden.
Das mag einigen Lesern bestimmt bereits sehr hoch erscheinen, vergleicht man diese Werte mit der üblichen Roundtrip-Latenz eines guten Audiointerfaces, die bei 2 bis 3 Millisekunden liegt. Diese sehr direkte Ansprache erreicht das Plug-in nicht. Es darf zwar erwartet werden, dass mit der jährlich stark zunehmenden Geschwindigkeit der CPUs und immer mehr auf KI spezialisierte Prozessoren Software wie Vocoflex profitieren wird, aber aktuell muss man mit diesen Werten leben.
Praxis
Ich habe die Dreamtonics Vocoflex Vocal Transforming Software als Standalone-Version und AU-Plug-in auf meinem Apple Mac Mini mit M1 Prozessor und 16 GB RAM ausprobiert. Ich musste etwas experimentieren, bis das richtige Verhältnis zwischen Buffer und Realtime-Mode gefunden war. Ist der Buffer zu gering, wird der Prozessor durch Vocoflex überlastet. Ist er zu hoch, ist die Latenz nicht mehr live-tauglich. Auf der anderen Seite steht die Qualität der Bearbeitung. Im Lowest-Latency-Mode ist diese gerade noch ausreichend. Ich habe mich bei meinem Test für einen Mittelweg aus einem Buffer von 256 Samples und Low-Latency-Mode entschieden, also dem Modus mit der zweitgeringsten Latenz.

Nach dem Import aus einer Audiodatei wird das KI-Stimmmodell als Kette dargestellt
Wichtig ist, dass für den Live-Einsatz entweder das bearbeitete Signal überhaupt nicht hörbar ist oder nur das bearbeitete Signal. Es ist zunächst aufgrund der Latenz etwas gewöhnungsbedürftig, mit Dreamtonics Vocoflex zu singen. Ich bin ohnehin kein ausgebildeter Sänger und am Anfang irritierte mich die leichte Latenz stark. Abhilfe schaffte dann ein Kopfhörer, auf dem nur ein Signal zu hören ist: 100 % Vocoflex oder 100 % die Originalstimme. Bei einem Mix aus beidem ist eine Dopplung zu vernehmen, die stört. Das ging mir auch so, wenn ich das bearbeitete Signal über eine Monitorbox beim Singen wiedergegeben habe. Hier muss jeder für sich ausprobieren, welches Setting für das eigene Wohlbefinden und Timing am besten ist.
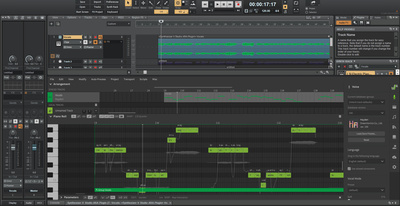
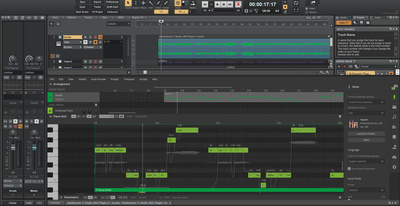
Für die Stimmanalyse habe ich mit Ultimate Vocal Remover 5 bekannte Stimmen aus dem Mix extrahiert und dann ein Sample davon in das Dreamtonics Vocoflex Live Vocal Transforming Plug-in geladen. Nach einer kurzen Analysezeit (abhängig von der Sample-Länge) steht dann ein Stimmmodul im Hauptfenster zur Verfügung. Mal wird es als gerade Kette angezeigt, mal als geschwungene Kette. Was die einzelnen Punkte und die Form der Kette bedeuten, erklärt aktuell leider niemand. Ein Handbuch ist zum Testzeitpunkt noch nicht verfügbar.
Verschiebt man bei nur einer einzelnen Stimme den Cursor, der unsere kleine Lichtquelle symbolisiert, tut sich nicht viel. Es sind eher Nuancen, die ich auf meinem Kopfhörer zu hören meine. Ganz anders, wenn man mehrere Stimmmodule im Hauptfenster hat. Nun kann man herrlich zwischen diesen morphen und ganz neue Stimmen kreieren und diese als Preset abspeichern. So wird tatsächlich aus einer langweiligen Männerstimme eine gehauchte Frauenstimme mit leichtem Soul-Charakter oder aus der Frauenstimme eine raue Männerstimme. Die Qualität hängt dabei von der CPU-Geschwindigkeit, der Qualität des Eingangssignals, der Aussteuerung und der Tonhöhe des Eingangssignals ab.

Morphing zwischen Stimmmodellen
Liegt der Ambitus (= Stimmumfang) des Eingangssignals außerhalb des Ambitus der Stimmmodelle, warnt das Dreamtonics Vocoflex Vocal Transforming Plug-in den Nutzer und fordert dazu auf, das zu korrigieren. Das kann man zum Beispiel mit dem unteren Pitch-Schieberegler tun. Allerdings ändert sich dann selbstverständlich auch die Tonhöhe des Ausgangssignals.


Da ich kein berühmter Sänger bin und Vocoflex per akustischem Wasserzeichen die Verwendung urheberrechtlich geschützten Materials nachverfolgen kann, habe ich mit der mir ebenfalls zum Test vorliegenden Software Synthesizer V kurze Vocal-Phrasen erzeugt und diese in Echtzeit mit dem Plug-in bearbeitet. Die gelegentlichen Glitches, die in den Klangbeispielen zu hören sind, sind schon in den Originaldateien aus Synthesizer V enthalten und stammen nicht vom Vocoflex Live Vocal Transforming Plug-in.

Vocoflex eignet sich auch gut zum Bearbeiten der künstlich erzeugten KI-Stimmen aus Dreamtonics Synthesizer V
Was mir aktuell noch fehlt, ist eine Möglichkeit, die einzelnen Stimmmodelle auf dem Bildschirm frei zu positionieren, um gezielter zu entscheiden, wie diese zueinander stehen sollen. Leider positioniert Dreamtonics Vocoflex die Modelle ziemlich willkürlich auf dem Bildschirm. Editiermöglichkeiten der Ketten gibt es derzeit ebensowenig. Aber da die Software noch einen Beta-Status hat, ist mit solchen Funktionen noch zu rechnen.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Bühnentauglichkeit
Ist das Dreamtonics Vocoflex Live Vocal Transforming Plug-in schon für den Bühneneinsatz geeignet? Ja und nein. Die Qualität ist in jedem Fall sehr gut und geht über das, was einige Bodentreter für die Gesangsfraktion zu bieten haben, deutlich hinaus. Problematisch ist aktuell die Latenz, denn der Output von Vocoflex ist doch hörbar verzögert, wenn man parallel dazu den eigenen Gesang hört. 45 Millisekunden erscheinen nicht viel, sind jedoch genau an der Grenze der Wahrnehmungsschwelle für Echos, der sogenannten Echoschwelle. Diese liegt je nach Signaltyp bei 20 bis 52 Millisekunden. Allerdings ist die Echoschwelle stark vom Pegel des verzögerten Signals und vom Signaltyp.
Die Echoschwelle liegt für perkussive Signale niedriger als für flächige Signale, zu denen Gesang zählt. Eine Lösung wäre also, das bearbeitete Signal dem unbearbeiteten Signal mit geringerem Pegel beizumischen. Das funktioniert dann gut, wenn das Geschlecht nicht mit dem Dreamtonics Vocoflex Vocal Transforming Plug-in verändert wurde, sondern nur leicht der Charakter der Stimme. Eine andere Möglichkeit ist, den Effekt nur auf dem FoH-System wiederzugeben, während auf dem Monitorsystem der unbearbeitete Gesang zu hören ist. So richtig glücklich macht aber keine der beiden Lösungen.
Nun stellt sich natürlich die Frage, warum Sängerinnen und Sänger auf der Bühne überhaupt ihre Stimme komplett verändern wollen. Schließlich ist die Stimme doch ein Charaktermerkmal und eine Stimme, die nicht zur Persönlichkeit auf der Bühne zu passen scheint, wirkt fehl am Platz und irritiert das Publikum. Doch gerade im Bereich von EDM und Co. werden im Studio Stimmen häufig stark bearbeitet und verfremdet. Diese Effekte dann live auf die Bühne zu bringen, ist nicht gerade trivial und hier kann die Vocoflex Live Vocal Tranforming Software unterstützen.
In jedem Fall sollte ein möglichst schneller Rechner verwendet werden und ein Plug-in mit Low-Latency-Treibern, um die Gesamtlatenz im Rahmen zu halten.
Im Studio

Plug-in in Ableton Live 12
Der Einsatz von Dreamtonics Vocoflex Vocal Transforming im Tonstudio hat allerdings kaum Einschränkungen, da hier im Bearbeitungsprozess nach der Aufnahme der Originalgesangsspur die Latenz keinerlei Rolle mehr spielt. Ob nun für EDM-Tracks oder für Chorspuren, Vocoflex lässt sich im Tonstudio vielfältig einsetzen. Immer dann, wenn ein einzelner Sänger auch die Chöre eingesungen hat, klingt das Gesamtergebnis eher ernüchternd. Mit dem Gender Transforming durch Dreamtronics Vocoflex lässt sich dem entgegenwirken und aus einer Tenorstimme eine Alt- und eine Sopranstimme generieren oder auch einfach ein anderer Stimmklang erzeugen, ohne gleich das Geschlecht zu verändern.
Im Zusammenspiel mit Synthesizer V entstehen Vocal-Skizzen, die von Komponisten und Produzenten als Vorlage für Sängerinnen und Sänger genutzt werden können oder im Rahmen von EDM-Tracks diese ganz ersetzen. Da sich die kleine Lichtquelle in der Matrix über MIDI bewegen lässt, kann man sogar über die Automation in der DAW das Morphing steuern. Mit einem Joystick oder X/Y-Pad an einem Masterkeyboard sollte sich das sogar in Echtzeit erledigen lassen. Dreamtonics Vocoflex wird im Tonstudiosektor bestimmt ebenfalls experimentierfreudige Freunde finden.
Was mir für den Studioeinsatz noch fehlt, wäre ein Export der Stimmmodelle nach Synthesizer V. Zwar kann man das Dreamtonics Vocoflex Vocal Transforming Plug-in einfach auf eine Synthesizer V Spur in der DAW laden, aber besser wäre es, wenn man die mit Vocoflex erzeugten Stimmtransformationen direkt in Synthesizer V importieren und dort weiterbearbeiten könnte, um diese dann schon im Renderprozess mit in die Audiodatei zu rendern.






Hallo Markus, vielen Dank für den Test. Im Beta-Stadium befindet sich die Software wohl nicht mehr, weil im Dreamtonics Store die SW mit dem Einführungsdiscount zu beziehen ist.
Mich würde interessieren, wie denn nun die Qualität der transformierten Stimmen ist. Sprich, kann ich auf meinen Vocalgesang einen Gesang von Künstler XY legen, der vom Original „fast“ nicht zu unterscheiden ist. Solche AI Transformationen gibt es ja schon. Du zeigst in einem Fenster den Import verschiedener Künstler, aber hören können wir das ja nicht. Bitte mal eine Einschätzung geben. Auf YouTube gibt es ja auch noch keine wirklichen guten Hörbeispiele. Vielleicht wäre es schön, wenn Du noch Demo-Beispiele bringst.
Kann man auch deutsche Sprache transformieren, die sich noch gut anhört? Leider gibt es keine Demo-Version. PS: Im Text sprichst Du von einer Einführung im Jahr 2023.. Danke schon mal.
@iOwner Hi,
die Software, die ich zum Testen hatte, war noch als Beta markiert. Ich vermute aber, dass da nichts mehr verändert wurde.
Alle Hörbeispiele wurden mit den Analysen gemacht, die du auch in den Screenshots sehen kannst.
Ich habe es mit meiner eigenen Stimme ausprobiert. Ich habe keine gute Gesangsstimme. Mich irritiert das zu sehr, wenn ich ins Mikrofon singe und die Stimme, die ich dann aus den Lautsprechern höre, anders klingt. Mit Kopfhörern war es etwas besser, aber man nimmt ja immer auch seine eigene Stimme über die Kopf- und Brustresonanzen wahr.
Das Resultat klingt natürlich nicht wie Whitney, Mariah, Freddie oder Michael. Es sind Tendenzen zu erkennen. Aber: Je mehr das Original von der analysierten Stimme abweicht, desto weiter weg ist auch das Resultat. Deshalb habe ich mit Synthesizer V eine Männerstimme und eine Frauenstimme generiert und dann damit herumgespielt. Es geht nicht so sehr darum, eine Kopie zu erstellen, sondern darum, dass du z. B. für Dopplungen oder Chorgesang eine Stimme erzeugen kannst, die nicht deine eigene ist. Das klingt wesentlich natürlicher als mehrfach die gleiche Stimme zu nutzen.
Das war aber auch alles nicht Ziel des Tests. Man hat mir das Plug-in als Live-tauglich vorgestellt und das habe ich überprüft. Es wird noch einen Studiotest zu Synthesizer V geben, da ist dann das Plug-in hier bestimmt auch noch einmal mit dabei.
@Markus Galla Alles klar. Die Originalstimmen hätte ich ehrlich nicht rausgehört. Ich hatte mir mehr davon versprochen. Warum man dann seine Stimme live noch mal verfremden möchte, verstehe ich auch nicht. Aber schon interessant, was auch schon geht.